Sounds: My Most Comprehensive Feature Yet
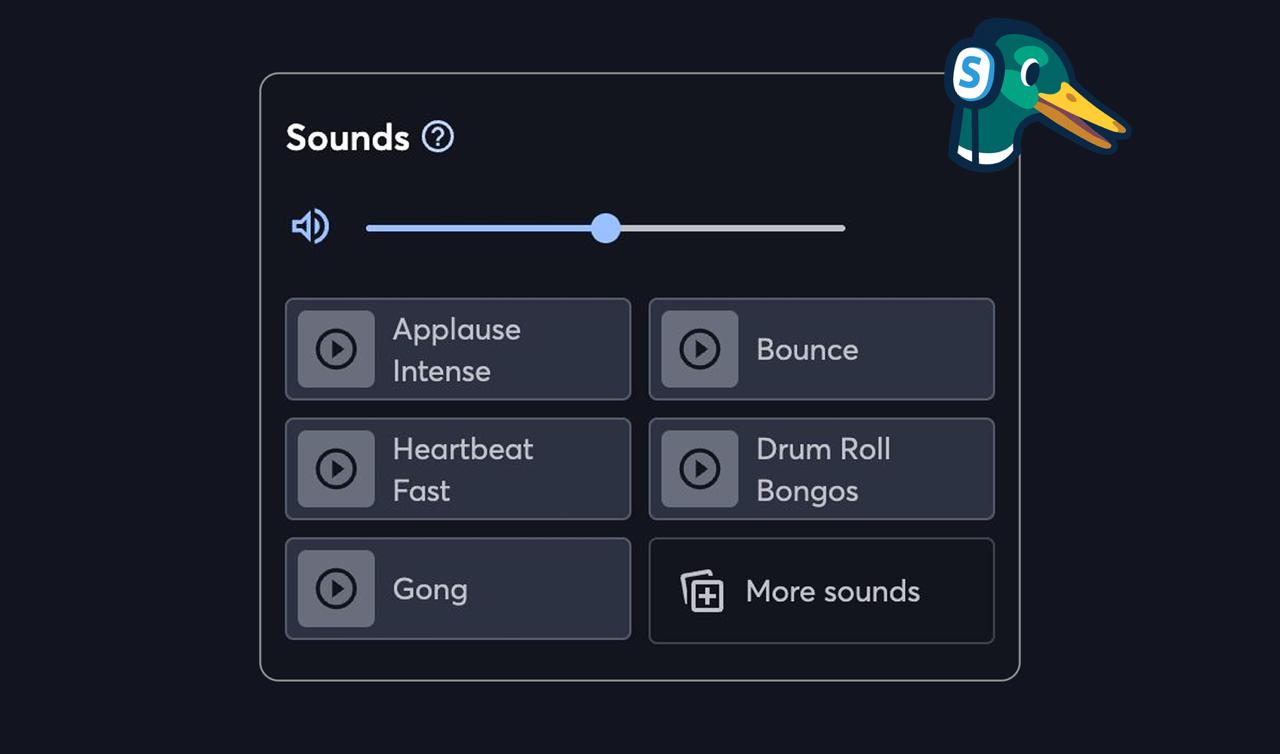
As part of the new QoX squad, I recently worked on implementing “Sounds”. StreamYard has had “Background Musics” in the “Media Assets” tab for a long time - this allows you to play any of the 8 example musics we provide, or to add your own and play them during a broadcast. We offer the ability to loop them, and fade in and out.
However, we had noticed a desire in the community to add a very similar feature but for sounds - short, usually below 5 seconds, and used mostly as a reaction or to emphasize something. And so I got to work.
By the way, these kinds of tasks are exactly where Claude Code shines. This task was mostly vibe coded, and I managed to bring the ETA down from the originally estimated 10 full dev days to 4. Since background musics was already in the codebase and worked well, all I had to do was get Claude to gain context about this. Then I gave it a long prompt, with a step by step guide of how I wanted to implement this, mimicking the logic of musics but with slight tweaks to types and logic (like not adding the looping or fading functions). Then we implemented each step prompt by prompt, and there was very little I had to change from its output.
Sound Effects Implementation in StreamYard
Overview
StreamYard uses a WebRTC SFU (Selective Forwarding Unit) for real-time communication. The system consists of a message-based architecture where state changes are propagated through a WebRTC server to all connected clients. Think of it in the following way:
Single Room ├─ Shared Room State │ ├─ Configurations │ ├─ Layouts │ ├─ Music state │ └─ …etc └─ Multiple Clients ├─ Client 1 (unique connection) ├─ Client 2 (unique connection) └─ Client N (unique connection)
So when implementing sound effects, the first step was to add this new type of asset throughout the entire stack, from the backend storage, to the message types and frontend playback controls.
Core Components
This implementation was the most comprehensive I have done yet because it spanned most of the codebase. It is by far the task I have completed so far which needed the most context, and to be very careful when adding and releasing code.
- Backend Asset Management
- Janus Message System
- Frontend State Management
- UI Components
Implementation Details
1. Backend Asset Model
Luckily, the backend implementation was very simple. In StreamYard, a user can create “brands” and each brand has its own set of media assets. Thus, we have shared controllers for all asset operations, and I just needed to add 'sounds' as a new asset type to the assets model:
1
2
3
4
5
6
7
8
const validBrandWithAssets = validBrand.keys({
backgrounds: Joi.array().items(validAsset).required(),
logos: Joi.array().items(validAsset).required(),
musics: Joi.array().items(validAsset),
overlays: Joi.array().items(validAsset).required(),
// Added sounds support
sounds: Joi.array().items(validAsset),
});
And then add handling.
2. WebRTC Message System
Now is where we need to define the message types and add them for sound control:
1
2
3
4
5
6
7
8
9
10
11
12
13
// Inbound messages (from clients)
export const inMessageTypes = [
// ... existing messages
'updateMusicAssetState',
'updateSoundAssetState', // Added for sounds
];
// Outbound messages (to clients)
export const outMessageTypes = [
// ... existing messages
'musicStateAssetUpdated',
'soundStateAssetUpdated', // Added for sounds
];
The sound state updates are handled similarly to music’s. Basically, when we receive updateSoundAssetState, we run some logic: first we calculate timing updates to handle synchronization of audio timing across clients, and then we update the state by merging the existing state, the new changes and the calculated time updates. Then we have callOnClients('soundStateUpdated')(soundState), which broadcasts the updated state to all connected clients in the room, which triggers their local state updates.
3. Room State Management
Rooms now track both music and sound states:
1
2
3
4
5
6
7
8
9
10
let soundState = {
...initialSoundState,
calibratedStartTime: calibratedSoundStartTime,
};
const backgroundSound = BackgroundAudio({
emitter: new Emitter(),
getState: () => soundState,
type: 'sound',
});
4. Sound Assets
To make the feature discoverable, especially to old users, it is important to have a few example assets always available for them to test it out. Thus, and since Splice is also owned by Bending Spoons, I ran a script to upload some example assets to our StreamYard s3 bucket, and then call them in the codebase. I literally asked ChatGPT to analyze the massive Splice JSON, which has 150+ sound assets, and pick the ones it thought were best as examples for StreamYard users, and generate the script. The script was something like:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
const fs = require('fs');
const path = require('path');
const https = require('https');
const { execSync } = require('child_process');
const { Storage } = require('@google-cloud/storage');
// Initialize Google Cloud Storage, of course I needed to have the necessary permissions for this
const storage = new Storage();
const bucket = storage.bucket('dummy-bucket');
const soundData = [
// json data I got from Splice codebase
];
// Function to download file
function downloadFile(url, outputPath) {
return new Promise((resolve, reject) => {
const file = fs.createWriteStream(outputPath);
https.get(url, (response) => {
if (response.statusCode !== 200) {
reject(new Error(`Failed to download: ${response.statusCode}`));
return;
}
response.pipe(file);
file.on('finish', () => {
file.close();
resolve();
});
file.on('error', (err) => {
fs.unlink(outputPath, () => {}); // Delete partial file
reject(err);
});
}).on('error', (err) => {
reject(err);
});
});
}
// Function to convert audio to MP3 using ffmpeg
function convertToMp3(inputPath, outputPath) {
try {
execSync(`ffmpeg -i "${inputPath}" -acodec mp3 -y "${outputPath}"`, { stdio: 'inherit' });
return true;
} catch (error) {
console.error(`Error converting ${inputPath}:`, error.message);
return false;
}
}
// Function to get file size and duration, since this metadata is needed for the StreamYard codebase
function getAudioInfo(filePath) {
try {
// Get file size
const stats = fs.statSync(filePath);
const bytes = stats.size;
// Get duration using ffprobe
const durationOutput = execSync(`ffprobe -v quiet -show_entries format=duration -of csv=p=0 "${filePath}"`);
const duration = Math.round(parseFloat(durationOutput.toString().trim()) * 1000); // Convert to milliseconds
return { bytes, duration };
} catch (error) {
console.error(`Error getting audio info for ${filePath}:`, error.message);
return { bytes: 0, duration: 0 };
}
}
// Function to upload to Google Cloud Storage
async function uploadToGCS(filePath, fileName) {
try {
const destination = `some_path`;
await bucket.upload(filePath, {
destination: destination,
metadata: {
cacheControl: 'public, max-age=31536000',
},
});
console.log(`✅ Uploaded ${fileName} to gs://dummy-bucket/${destination}`);
return true;
} catch (error) {
console.error(`❌ Error uploading ${fileName}:`, error.message);
return false;
}
}
// Main processing function
async function processSound(sound) {
const tempDir = './temp_sounds';
if (!fs.existsSync(tempDir)) {
fs.mkdirSync(tempDir);
}
const originalExt = path.extname(sound.audio_url);
const tempFile = path.join(tempDir, `${sound._identifier}${originalExt}`);
const mp3File = path.join(tempDir, `sound_${sound._identifier}.mp3`);
try {
console.log(`📥 Downloading ${sound.name}...`);
await downloadFile(sound.audio_url, tempFile);
console.log(`🔄 Converting ${sound.name} to MP3...`);
const converted = convertToMp3(tempFile, mp3File);
if (!converted) {
throw new Error('Conversion failed');
}
console.log(`📊 Getting audio info for ${sound.name}...`);
const { bytes, duration } = getAudioInfo(mp3File);
console.log(`☁️ Uploading ${sound.name}...`);
const uploaded = await uploadToGCS(mp3File, `sound_${sound._identifier}.mp3`);
if (uploaded) {
// Clean up temp files
fs.unlinkSync(tempFile);
fs.unlinkSync(mp3File);
return {
name: sound.name,
file: `\${SOUND_SAMPLES_BUCKET}/sound_${sound._identifier}.mp3`,
duration,
bytes
};
} else {
throw new Error('Upload failed');
}
} catch (error) {
console.error(`❌ Error processing ${sound.name}:`, error.message);
return null;
}
}
// Main execution
async function main() {
console.log('🚀 Starting sound processing...');
const results = [];
for (const sound of soundData) {
const result = await processSound(sound);
if (result) {
results.push(result);
}
}
// Clean up temp directory
const tempDir = './temp_sounds';
if (fs.existsSync(tempDir)) {
fs.rmSync(tempDir, { recursive: true });
}
// Generate the TypeScript array
console.log('\n🎉 Processing complete! Here\'s your TypeScript array:\n');
console.log('const SOUND_SAMPLES: SoundSampleDefinitions[] = [');
results.forEach((sound, index) => {
const comma = index < results.length - 1 ? ',' : '';
console.log(`\t{`);
console.log(`\t\tname: '${sound.name}',`);
console.log(`\t\tfile: \`${sound.file}\`,`);
console.log(`\t\tduration: ${sound.duration},`);
console.log(`\t\tbytes: ${sound.bytes},`);
console.log(`\t}${comma}`);
});
console.log('];');
console.log(`\n✅ Successfully processed ${results.length} out of ${soundData.length} sounds`);
}
// Run the script
main().catch(console.error);
And boom, I ran node sound_upload_script.js, which generated the following Terminal output:
1
2
3
const SOUND_SAMPLES: SoundSampleDefinitions[] = [
//examples
];
And I was done with this step. A truly productive 5 minutes of work xD.
State Management and UI Implementation
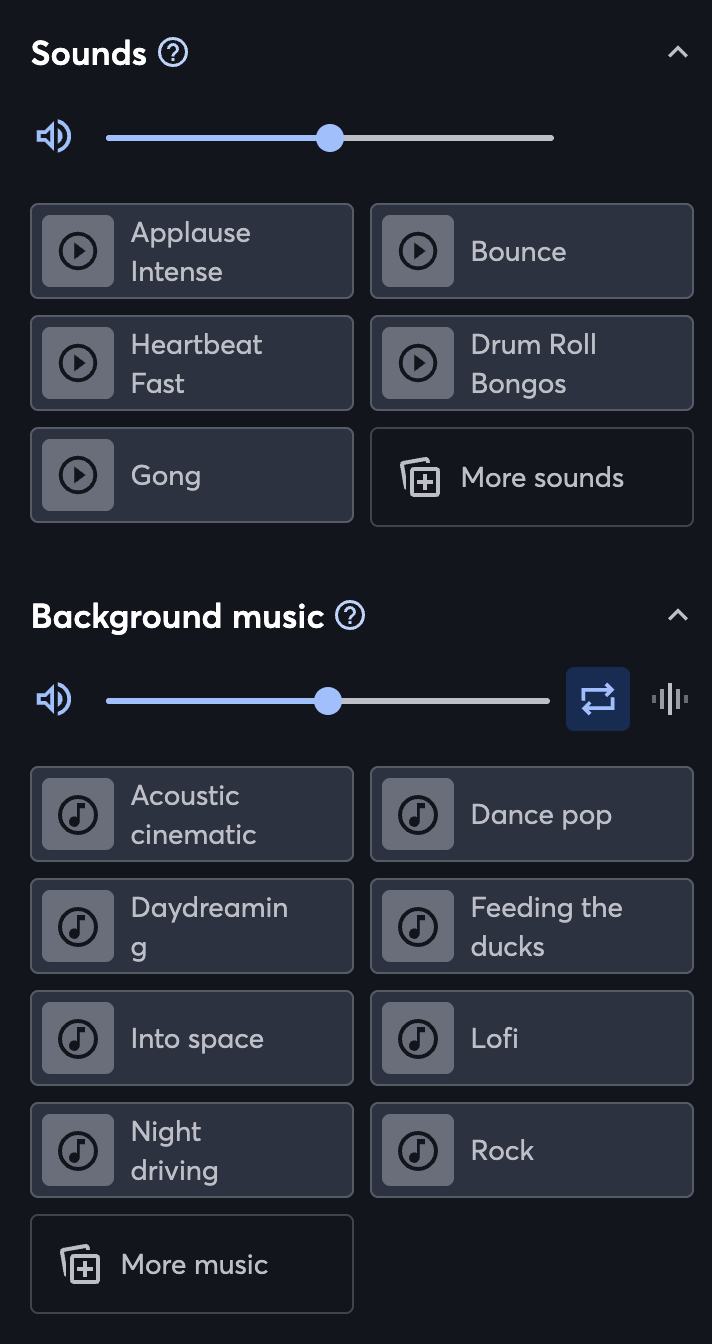
At this point, I was basically done. It was now a matter of adding the ducks and epics necessary to handle sound state in the frontend, and refactor the UI components that background musics used to also be able to handle sounds, since they are basically the same.
Monitoring and Metrics
Now I just had to make sure I had the necessary logging for sound actions and updates, to check for errors and log the state where necessary as done for musics, and to add metrics so we could track user adoption. About 10% of new users use the feature, and it has a retention of about 50% (% of users that have used it once and use it again). Not a massive adoption, but in line with expectations and quite successful for a QoX feature (since the goal is to improve the product in the long-run).
Conclusion
The sound effects implementation leveraged AI and the existing background music infrastructure to add a sound-specific feature in record time. By following the same patterns used for music (WebRTC messages, state management, asset handling), I maintained consistency while giving AI the necessary context to add a new functionality nearly autonomously.